A large organization launches over a hundred AI initiatives across departments. The first week, enthusiasm is high. People try new tools, share screenshots, and talk about them at lunch.
By week four, most have gone back to doing things the way they always did. The tools are still there. The adoption is not.
Without central coordination, this pattern compounds. One municipality inventoried 169 separate AI initiatives across teams, none connected. That kind of fragmentation does not just waste budget. It creates a risk nobody is managing.
This pattern plays out in organizations of every size. The technology works, the models perform. What is missing is the organizational capability to turn experiments into production-ready systems.
Giving people tools is not adoption
Vera Schut, COO and co-founder of NXTminds, sees it up close. Her firm helps organizations build AI capability by providing temporary expertise in AI, data, and IT. The pattern she describes is consistent.
AI knowledge is a muscle you have to develop. One training session and an enterprise license are not enough. Structural change requires people who understand the technology well enough to apply it to their own work, repeatedly, without external hand-holding.
The bottleneck is rarely enthusiasm. Most teams are genuinely interested. The problem is time.
People in organizations are driven by their inbox, Vera Schut observes. Put a strategic AI project on top of their daily workload, and even the most motivated employees quietly drop it after a few weeks.
The impact of integrating AI into an existing workflow is often more disruptive than leaders anticipate. It changes how people prioritize, collaborate, and make decisions.
Leaders who want AI adoption need to free up capacity first. That means budget, dedicated time, and a clear answer to one question. What does success look like in twelve months?
Three models, one question
How you organize AI capability depends on where your organization stands. There is no single correct model, but three keep appearing.
A Center of Excellence centralizes AI expertise, tooling, and governance within a single team. This works well for organizations that need control, especially in regulated industries or when working with sensitive data.
In episode 6 of the Your AI Your Way podcast, Nick Brummans, Product Owner AI, describes running exactly this model at Eindhoven University of Technology. His team at the Supercomputing Centre started with a single AI engineer 18 months ago and has grown to five, supporting researchers, students, and, increasingly, industry partners. Each project adds to a shared knowledge layer, making the next project faster.
A hub-and-spoke model keeps a central hub for guardrails and frameworks while letting business units identify their own needs. The hub sets the rules. The spokes bring the actual problems.
A community-led approach relies on informal networks of enthusiastic employees who share knowledge and experiment together. This works in early stages but carries risk. Without oversight, smart individuals end up running AI projects that leadership knows nothing about, including the associated compliance risks.
Every organization lands somewhere different. The question that matters is which model aligns with your maturity and your risk profile.
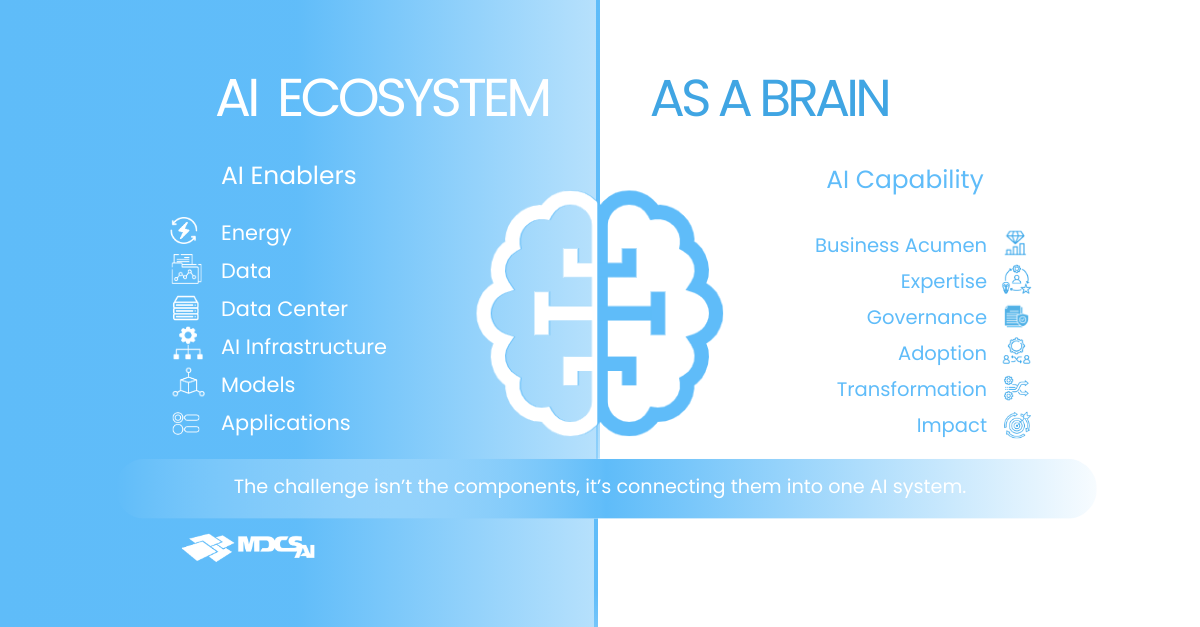
Two hemispheres, one brain
Think of an AI ecosystem as a brain with two hemispheres. The right side is infrastructure, software, and compute. The left side is the AI Center of Excellence, the skills and capabilities needed to anchor transformation in the organization. One without the other produces noise, not results.
Access to powerful compute is easier than ever. Using it well is a different matter.
Nick Brummans uses a metaphor that sticks. Every compute platform is a racetrack. If you want to race on it, you need to build a race car and learn the track. That takes trial and error, or a specialist who already knows the corners.
In practice, his team sees researchers and companies struggle with advanced AI platforms because software libraries have not kept pace with the latest hardware. Getting full performance from new GPU architectures requires writing code at a lower level than most teams are used to. Without that knowledge, expensive hardware sits underutilized.
The efficiency gap is significant. With proper guidance from a Center of Excellence, workloads can run up to six times faster on the same hardware.
There is a simpler lesson underneath. Match the platform to the workload. An LLM serving internal users does not require the most expensive GPU cluster available. It needs enough memory and a setup that handles uneven traffic.
Putting every workload on the most advanced infrastructure is like driving a Formula One car to the supermarket.
Guardrails before you scale
Before an organization scales AI across teams, three things need to be explicit.
Ownership. Who decides which AI tools are used, which data they access, and which models are approved? If this is unclear, the answer defaults to whoever moved fastest. That is how uncontrolled AI projects end up running on infrastructure nobody vetted.
Governance. What are the boundaries? Where do models run, and under which jurisdiction is data stored? For organizations handling sensitive information, these questions connect directly to sovereignty. The ability to know and control where your workloads and data reside is a business requirement, not a technical preference.
Security and compliance. Every AI tool that connects to company data creates an attack surface. Every model hosted externally raises questions about data residency. Buying AI-enabled software without asking these questions is a risk that compounds with every new deployment.
“Where does that model run? Where does the data go? What does this mean for compliance?” These are the questions Vera Schut hears organizations ask too often, too late.
Build the muscle while you run
External expertise accelerates the start. A specialist who has seen 10 organizations build AI capabilities can help you avoid the mistakes you would make while figuring it out on your own. Vera Schut compares it to shortening the learning curve.
The goal is not permanent dependence on outside help. It is a repeatable operating model and a growing internal skill base. A Center of Excellence that captures lessons from every project, applies them to the next one, and builds a team that knows when to use expensive compute and when a simpler platform will do.
That also means accepting that what counts as good capability today may be outdated in six months. The landscape moves fast. Building a team that keeps learning is more valuable than hiring for a fixed set of skills.
The most transformative results come when organizations redesign processes with AI built in, rather than layering AI on top of existing processes. That takes a capability that goes beyond tooling. It requires people who understand the business problem, the technical possibilities, and the guardrails around both.
Organizational choices and platform choices need to happen together. The operating model shapes what you can build. The infrastructure determines where it runs, how safely, and at what cost.
Want to sense-check which operating model and platform setup fit your organization’s maturity and risk profile? Get in touch with the AI experts at MDCS.ai.





